外观
Chapter 2 数理统计
Part 1 大数定理与中心极限定理
· 切比雪夫不等式
设随机变量 的期望为 ,方差为 ,则对于任意给定的 ,有:
或等价地
说明:
- 该不等式给出了随机变量偏离期望值的概率上界
- 方差 越小,偏离概率的上界越小
- 适用于任何具有有限方差的随机变量
· 大数定律
大数定理:在大量重复试验中,样本平均数会趋近于理论期望值。换句话说,当试验次数足够多时,实验结果的平均值会接近预期的长期平均值。
切比雪夫大数定律 (Chebyshev's LLN).
条件:
- 随机变量序列 相互独立
- 数学期望 和方差 都存在
- 方差有公共上界: ()
结论: 对任意 ,有
核心思想: "只要方差有限,大量重复试验的平均值会接近期望值"
伯努利大数定律 (Bernoulli's LLN).
条件: 设 , 是 次伯努利试验中事件 发生的次数
结论: 对任意 ,有
核心思想: "投硬币这类事情,大量地实验结果里,频率会接近概率"
辛钦大数定律 (Khinchin's LLN).
条件: 随机变量序列 相互独立同分布,且
结论: 对任意 ,有
核心思想: "同一类型的随机变量,大量样本的平均值会接近期望值"
· 中心极限定理
个随机变量,它们相互独立且服从同一种分布规律(独立同分布),期望值为,方差为,有:
Part 2 数理统计基本概念
· 总体与样本
总体:研究对象某项数量指标的全体称为总体。构成总体的每个成员称为个体。例如,研究一批机器的寿命,则全部机器的寿命构成问题的总体,每一台机器的寿命是一个个体,总体是寿命 服从的分布。
注:总体分布的类型有时是明确的,统计的任务是确定未知参数,即参数估计;有时是不明确的,需要先对分布进行假定,再估计未知参数。
样本:在相同条件下对总体 进行 次简单随机抽样,得到的 个观察结果 相互独立且同分布于总体 ,称 为来自总体 的一个简单随机样本,简称样本,其中 称为样本容量。抽样得到的一组实数记为 ,称为样本观察值,简称样本值。
例如,从该批机器中随机抽 20 台测定其寿命,即得容量为 20 的样本观测值 。抽取前无法预知每台样品的寿命,因此样本 是随机变量。
- 有些教材中为简单化处理,统一用 表示样本和样本值。
- 从总体中抽样的方法是多种多样的,本课程仅研究简单随机样本,即 相互独立且同服从于总体分布。
· 经验分布函数
定义 设 为总体 的一个样本,其样本值为 ,则称函数
为样本值 的经验分布函数。
若已知样本值 的频数、频率分布表为
指标 ... 频数 ... 频率 ... 则经验分布函数
格里文科定理:对于任意实数 ,当 时 以概率 1 一致收敛于分布函数 。即当 充分大时,经验分布函数的任一个观察值 是总体分布函数 的良好近似,从而实际上可当作 来使用。
· 统计量
定义:不含任何未知参数的样本函数 称为统计量。设 是对应于样本 的样本值,则称 是 的观测值,称为统计值。
常用统计量:
设 为总体 的一个样本, 为样本容量
- 样本均值
- 样本方差
推导过程
- 样本标准差
- 样本 阶原点矩
- 样本 阶中心矩
· 样本统计量的数字特征
已知 为来自总体 的样本,
· 三大抽样分布
**卡方分布 (Chi-square Distribution) **
定义 设 是来自总体 的样本,则称统计量
服从自由度为 的 分布,记为 。
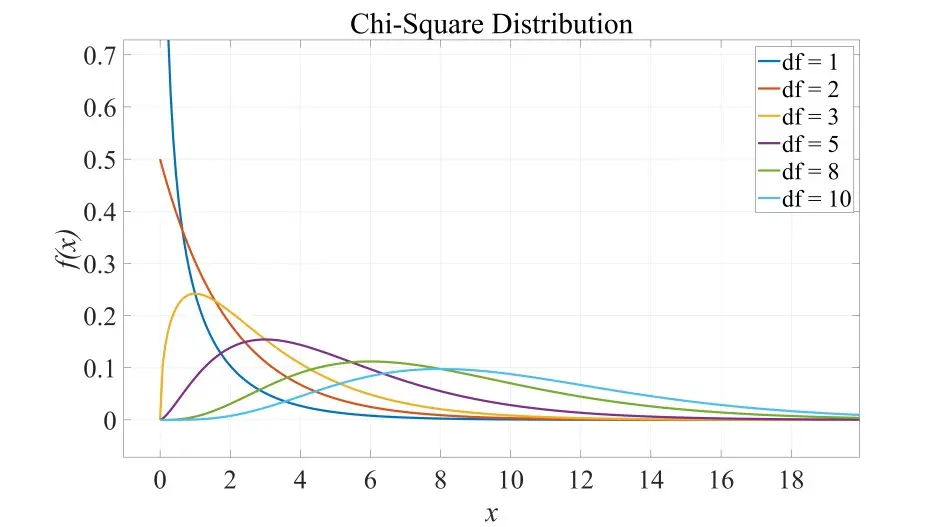
性质
- 可加性:设 , ,并且 , 独立,则
数学期望和方差(背):若 ,则有 ,
分位点
分位点定义 设有分布函数 ,对给定的 ,若有
则称点 为 的上 分位点。
的分位点 设 ,对给定的 ,若有 满足
则称 为 分布的上 分位点。
t分布 (Student's t-Distribution)
定义 设 , ,且 独立,则称随机变量
服从自由度为 的 分布,记为
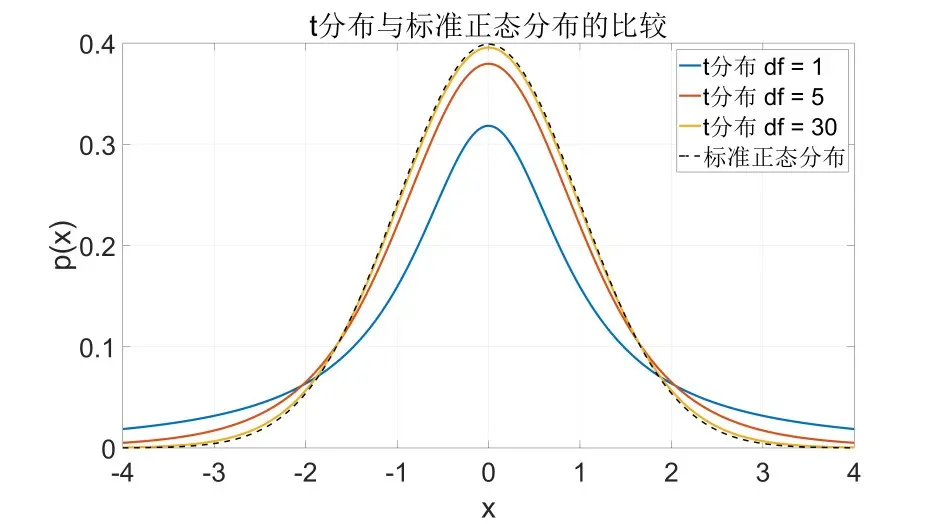
性质
奇偶性: 分布的概率密度 图像为偶函数。
分位点 对于给定的 ,称满足条件 的点 为 分布的上 分位点。易得
结论
- 自由度 的 分布是标准柯西分布,它的期望不存在。
- 自由度 的 分布期望存在且为 0。
- 当自由度较大( )时, 分布与标准正态分布 近似。
F分布 (F-Distribution)
定义 设 , ,且 独立,则称随机变量
服从自由度为 的 分布,记为 , 称为第一自由度, 称为第二自由度。
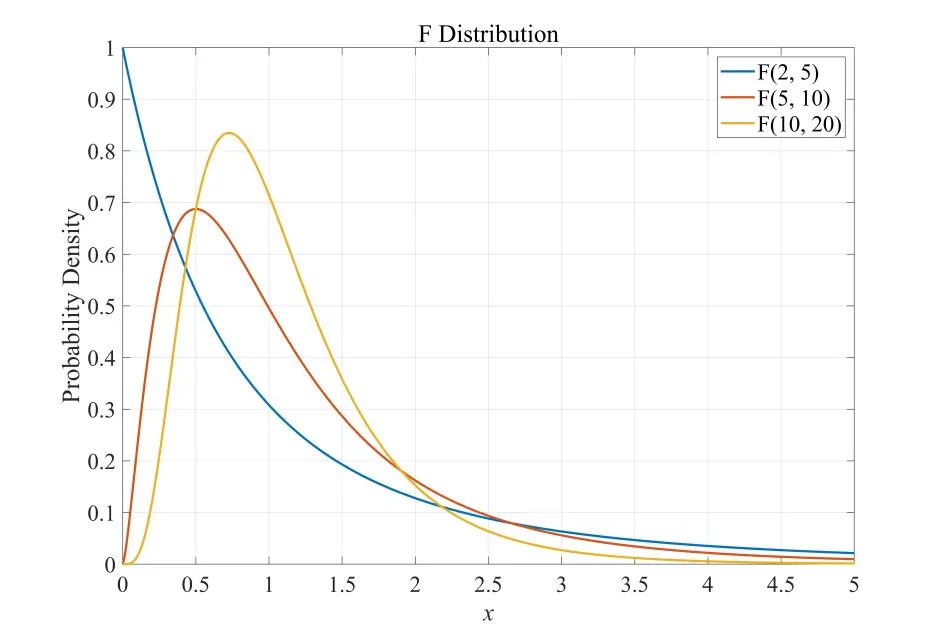
性质:若 ,则
分位点:对于给定的 ,称满足条件 的点 为 分布的上 分位点。易得
· 分位点
/Definition/
分位数定义:对于遵循某个分布的随机变量 ,给定一个参数 ,如果存在一个值满足:
则称 为该分布的上 分位点。
不同分布的上 α 分位点表示
卡方分布:上 分位点记为 .
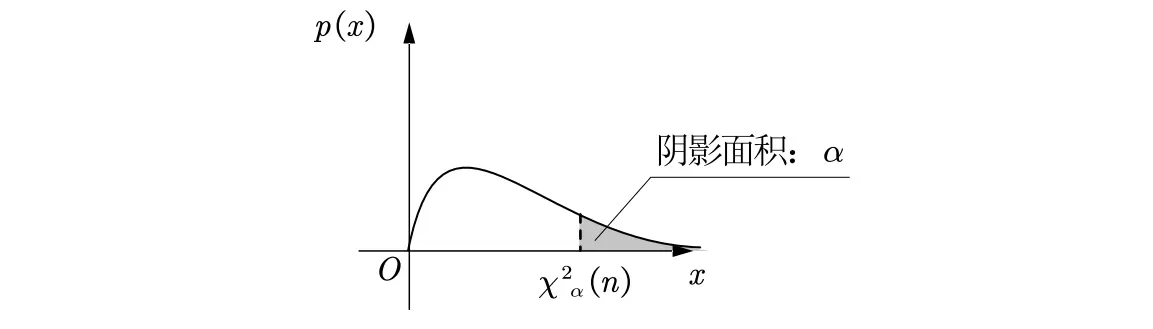
t分布:上 分位点记为 .
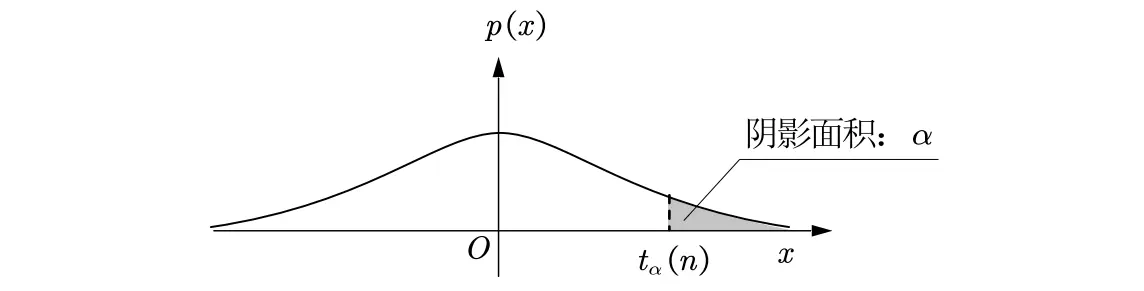
F分布:上 分位点记为 .
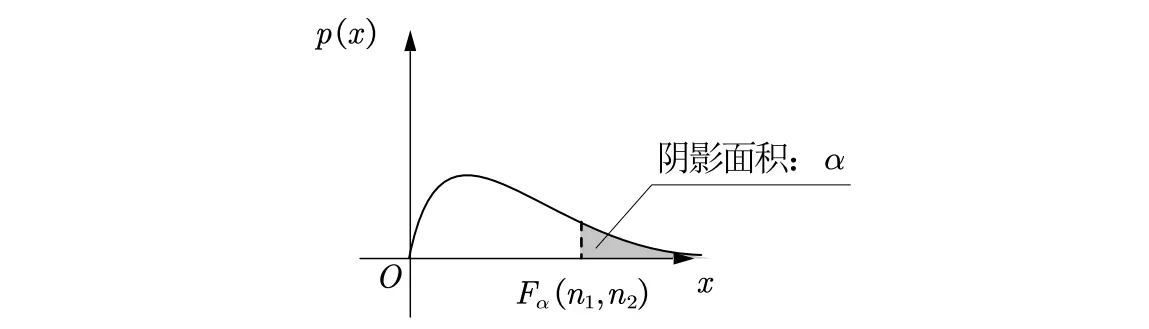
· 正态总体抽样分布
一个正态总体:假设 是来自正态总体 的样本,样本均值与样本方差分别是
样本均值 与样本方差 相互独立;
两个正态总体:
设 是取自总体 的一个样本, 是取自总体 的一个样本,且这两个样本相互独立,即假定 是 个相互独立的随机变量,则有
证明:
与 相互独立,故
标准化有
证明:
,且它们相互独立,故
当 时,有
其中
证明:由
,且相互独立,根据可加性,
由
,且 与 相互独立,故
Part 3 参数估计
· 点估计
点估计
设 是总体 的未知参数,用统计量 来估计 ,称为 的估计量。对于样本的一组观察值 ,代入 的表达式中所得的具体数值称为 的估计值。这样的方法称为参数的点估计。
矩估计
用样本矩去估计相应总体矩,或者用样本矩的函数去估计总体矩的同一函数的估计方法就是矩估计。
设总体 的概率分布中含有 个未知参数 。假定总体的 阶原点矩存在,记
为样本 阶矩,令
则此方程组的解 称为参数 的矩估计量。矩估计量的观察值称为矩估计值。
最大似然估计(极大似然估计)
(1) 设总体 的概率分布为 (当 为连续型时,其为概率密度函数,当 为离散型时,其为分布律), 为未知参数, 为样本观察值,则
称为 的似然函数。
(2) 对给定的 ,使似然函数达到最大值的 称为 的最大似然估计值,相应地 称为 的最大似然估计量。
(3) 最大似然估计的常用求解方法:由于 与 有相同的最大值点,若 可导,则可由对数似然方程组
求出 的最大似然估计量。需注意的是这一方法并不都是有效的,对于有些似然函数,其驻点或导数不存在,这时应考虑用其他方法求似然函数的最大值点。
· 估计量的评选标准
无偏性 设 为来自总体 的样本, 为 的一个估计量,如果 成立,则称估计量 为参数 的无偏估计。
有效性 设 都为参数 的无偏估计量,若 ,则称 比 有效。特别地,若对于 的任一无偏估计量,都有 ,则称 是 的最小方差无偏估计(最佳无偏估计)。
一致性 设 为未知参数 的估计量,若对任意给定的 ,都有
即 依概率收敛于参数 ,则称 为 的一致估计或相合估计。
· 区间估计
区间估计
设 为总体的未知参数, 和 均为估计量,若对于给定的 ,满足
,则称 为 的置信度为 的置信区间。通过构造一个置信区间对未知参数进行估计的方法称为区间估计。
单个正态总体的区间估计
设 为来自总体 的样本,则
(1) 当 已知时, 的置信度为 的置信区间为
(2) 当 未知时, 的置信度为 的置信区间为
(3) 当 已知时, 的置信度为 的置信区间为
(4) 当 未知时, 的置信度为 的置信区间为
双正态总体的区间估计
设 为其样本, 为其样本,且 与 独立。
(1). 当 都已知时: 的 的置信区间为
(2). 当 都未知时: 的 的置信区间为
其中
警告
特殊情形:
① 未知,但 较大时: 的 的置信区间为
② 未知: 的 的置信区间为
其中
分布为 。
- 已知: 的 的置信区间为
分布无参数的区间估计
设总体 分布, 为其样本,则 的 的置信区间为
单侧置信区间
设 为总体的未知参数,对于给定值 ,若 ,则称
· 单侧置信区间
为 的满足置信度 的单侧置信区间, 称为单侧置信下限。若 ,则称 为 的满足置信度 的单侧置信区间, 称为单侧置信上限。
例如,对于正态分布 , 未知,可得 的置信水平为 的单侧置信区间为
单侧置信上限为
单侧置信下限为
亦即只需将双侧置信区间的上、下限中的“ ”改成“ ”,就得到相应的单侧置信区间的上限或下限了。
· 习题
/example/ 设 为总体 的一个样本,求下列概率密度中未知参数 的矩估计量和最大似然估计量。
概率密度函数:
其中 。
[矩估计].
计算总体期望:
解得 与 的关系:
用样本均值 代替 ,得到矩估计量:
[最大似然估计].
构建似然函数:
取对数似然函数:
对 求导并令导数为零:
解得最大似然估计量:
/example/
概率密度函数:
其中 。
[矩估计].
计算总体期望:
解得 与 的关系:
用样本均值 代替 ,得到矩估计量:
[最大似然估计].
构建似然函数:
取对数似然函数:
对 求导并令导数为零:
解得最大似然估计量:
Part 4 假设检验
· 假设检验的基本概念
假设检验
对总体的分布类型或分布中的未知参数作出假设,然后抽取样本并选择一个合适的检验统计量,利用检验统计量的观察值和预先给定的误差 ,对所作假设成立与否作出定性判断,这种统计推断称为假设检验。
若总体分布已知,只对分布中未知参数提出假设并作检验,这种检验称为参数检验。
假设检验基本思想的依据是小概率原理
小概率原理是指概率很小的事件在试验中发生的频率也很小,因此小概率事件在一次试验中几乎不可能发生。
当对问题提出待检假设 ,并要检验它是否可信时,先假定 正确。在这个假定下,经过一次抽样,若小概率事件发生了,就作出拒绝 的决定;否则,若小概率事件未发生,则接受 。
假设检验基本概念
在显著性水平 下,检验假设
当检验统计量取某个区域 中的值时,我们拒绝原假设 ,则称区域 为拒绝域(或否定域)。
假设检验过程
- 提出原假设和备择假设;
- 选取检验统计量;
- 确定拒绝原假设的域;
- 计算检验统计量的观察值并作出判断。
两类错误
人们作出判断的依据是一个样本,样本是随机的,因而人们进行假设检验判断 可信与否时,不免因误判而犯两类错误:
- 第一类错误: 为真,而检验结果将其否定,这称为“弃真”错误;
- 第二类错误: 不真,而检验结果将其接受,这称为“取伪”错误。 分别记犯第一、二类错误的概率为 ,即 拒绝 为真 , 接受 不真 。当样本容量 固定时, 越小, 就越大。一般采取的原则是:固定 ,通过增加样本容量 降低
假设检验与区间估计的联系 假设检验与区间估计是从不同角度对同一问题的回答,它们解决问题的途径是相通的。下面以正态总体 ,其中 已知,关于 的假设检验和区间估计为例加以说明:
假设 ,当 为真时,则 ,对于给定的显著性水平 , ,那么 的接受域为
即认为以 的概率接受 ,事实上,这个接受域也是 的置信度为 的置信区间。这充分说明两者解决问题的途径相同,假设检验判断的是结论是否成立,而参数估计解决的是范围问题。
· 正态总体参数的假设检验
一个正态总体的假设检验
设 为其样本,
(1) 已知,检验假设 。检验步骤为:
提出待检验假设 已知);
选取样本 的统计量
( 已知),在 成立时, ;
对给定的显著性水平 ,查表确定临界值 ,使得
计算检验统计量 的观察值并与临界值 比较;
作出判断:若 ,则拒绝 ;若 ,则接受 。
(2) 未知,检验假设
选取统计量
其中
当 为真时, ,拒绝域为 。
(3) 已知,检验假设
选取统计量
拒绝域为 或 。
(4) 未知,检验假设
选取统计量
当 为真时, ,拒绝域为 或 。
两个正态总体的假设检验
设 , , 和 分别是来自总体 和 的样本, 和 是相应的样本均值和样本方差
(1) 已知,检验假设 。
选取统计量
拒绝域为 。
(2) 未知,检验假设 。常见的三种特殊情况:
① 当 较大时:选取统计量
拒绝域为 。
② 时:选取检验统计量
当 为真时, ,显著性水平为 的拒绝域为 。
③ ,但 (配对问题):
令 ,则 ,其中 (未知)。此时检验假设等价于 。
选取统计量
拒绝域为 。
(3) 已知,检验假设 。
选取统计量
拒绝域为 或 。
(4) 未知,检验假设 。
选取检验统计量
当 为真时 ,显著性水平为 的拒绝域为
· 单侧检验
在假设检验中,如果只关心总体参数是否偏大或偏小,此时可将拒绝域确定在一侧,这种检验称为单侧检验。单侧检验可由双侧检验修改转化而得到。常用基本类型举例:
已知,检验假设
有时也写成
选取
拒绝域为
已知,检验假设
选取
拒绝域为
未知,检验假设
选取
拒绝域为
未知,检验假设
选取
拒绝域为
未知,检验假设
选取
拒绝域为
未知,检验假设
选取
拒绝域为
未知,检验假设
选取
拒绝域为
未知,检验假设
选取
拒绝域为
结束.
更新日志
2025/11/26 14:37
查看所有更新日志
fdf57-于c1b47-于f41af-于1595c-于348a6-于c9ee8-于a28aa-于